
Understanding MemGPT: Towards unlimited AI memory.

Have you ever interacted with ChatGPT and noticed that it sometimes forgets earlier parts of the conversation? This happens because Large Language Models (LLMs) like ChatGPT inherently lack state—they don’t retain memory of prior interactions. To tackle this, Charles Packer and collaborators from UC Berkley propose an innovative solution inspired by operating systems that could enhance the memory capabilities of LLMs. Before diving into their paper here is a simple breakdown of what we need to know:
Fundamentals:
Token: A very simple approach to breakdown sentences in words is based on whitespace for example sentence “Hello World!” will have tokens as [‘Hello’, ‘World!’] with token size of 2. Simple, right? However, this whitespace-based method has its limitations. Can you guess what they might be?
GPT models use what is known as Byte Pair Encoding which was originally developed to compress text in which we break words into meaningful subwords. It starts by treating each character in the text as a separate token then this process involves iteratively merging the most frequently occurring pairs of adjacent tokens (characters or sequences) to form longer tokens. This frequency-based merging continues until a specified vocabulary size is reached or a predetermined condition is met. The final vocabulary comprises individual characters, common subwords, and whole words.
Initial Tokens: ["H", "e", "l", "l", "o", " ", "w", "o", "r", "l", "d", "!"]
Identify and Merge Frequent Pairs: If "ll" is a common pair, it might merge first:
After merging "ll": ["H", "e", "ll", "o", " ", "w", "o", "r", "l", "d", "!"]
Repeat Merging Process: The process continues based on the frequency in the training data, merging pairs like "He", "ello", "wo", "rl", etc.
Resulting Tokens for "Hello world!": The final tokens depend on the training data's frequencies. An example outcome could be ["Hell", "o", "world", "!"].
Token Size: The number of tokens post-BPE processing depends on the applied merging rules. In this hypothetical example, the phrase results in 4 tokens: ["Hell", "o", "world", "!"]
Now that we understand tokens and token size lets look at Context Window:
The context window refers to the maximum number of tokens an LLM can consider at any given time. It's like the model's short-term memory.
For GPT-4, this window is approximately 8,000 tokens. This means it can keep track of and reference about 8,000 tokens at a time to generate responses or make predictions.
The context window size limits the amount of text the model can "see" or reference in generating coherent and contextually appropriate output. It's a significant factor in tasks that involve long conversations or in-depth analysis of large documents.
Glad you are still here, lets go ahead and understand what the paper is proposing.
Architecture:
As outlined in the paper, let's explore the proposed system architecture:
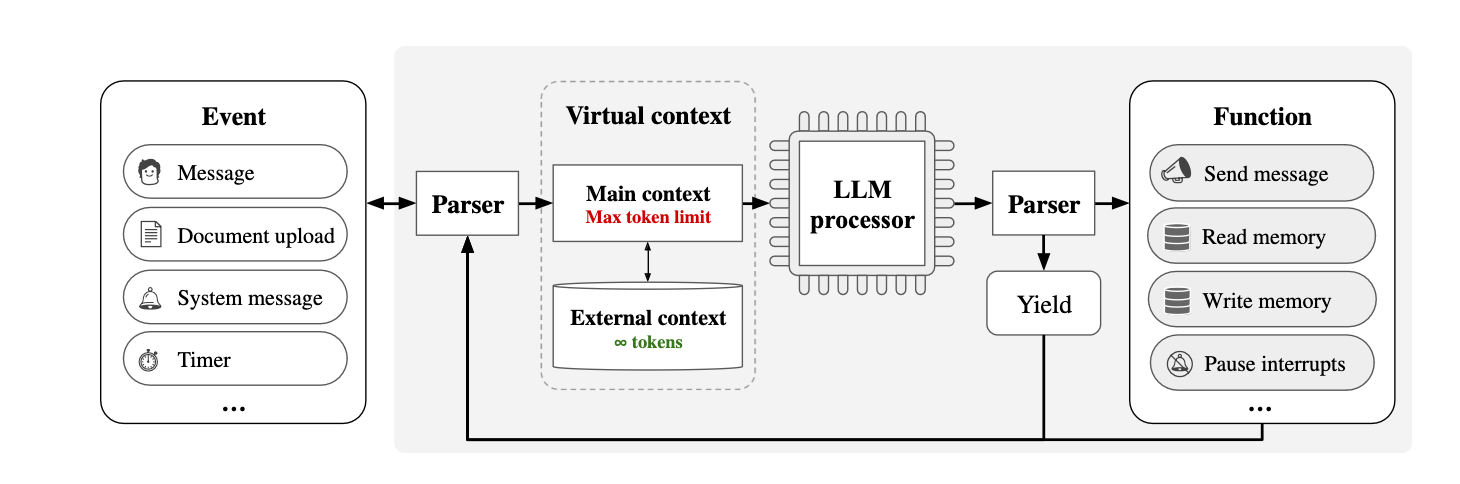
Event:
This is the input to the system, which can come in various forms such as a user's message, a document upload, system-generated messages, or a timer event. These events are what trigger the MemGPT system to process and respond.
Parser:
The parser interprets the incoming events and translates them into a format that the LLM processor can understand. It's like a translator that converts various types of inputs into a consistent set of instructions for the LLM.
Virtual Context:
This is the memory management system of MemGPT, divided into two parts:
Main Context: This is the active memory of the LLM, similar to the RAM in a computer. It has a maximum token limit, which means it can only hold a limited number of tokens at a time. This represents the current "focus" or "awareness" of the LLM.
External Context: This is like the long-term storage, similar to a computer's disk memory. It can hold an unlimited number of tokens but is not actively processed by the LLM. It stores additional information that the LLM can access when needed.
LLM Processor:
This is the core of the system, the LLM itself, which processes the main context. It takes the active tokens from the main context, processes them to generate a response or perform a function, and then produces output.
Functions:
These are actions that the LLM can perform as a result of processing the main context. They include sending messages, reading from or writing to the external context (memory operations), or pausing processing (interrupts).
Yield:
When the LLM processor reaches a point where it needs to wait for the next input or it has completed a task, it "yields". This is like taking a break until the next piece of information comes in.
Process Flow:
Here's how these components work together in a typical scenario:
An event occurs, such as a user sending a message.
The parser interprets the event and prepares it for the LLM processor.
The LLM processor checks the main context to see what it already knows and then processes the new information from the parser.
If the LLM needs more information or needs to store information, it uses functions to interact with the external context.
Once processing is complete or if it needs to wait for something, the LLM yields.
The system waits for the next event to start the cycle again.
Experiments:
Now, lets look at a few examples of this system in action from the paper and how everything ties in together. This paper discusses two use cases, one for Conversational Agents and the other for Document Analysis, lets look at one of the conversation agents example.
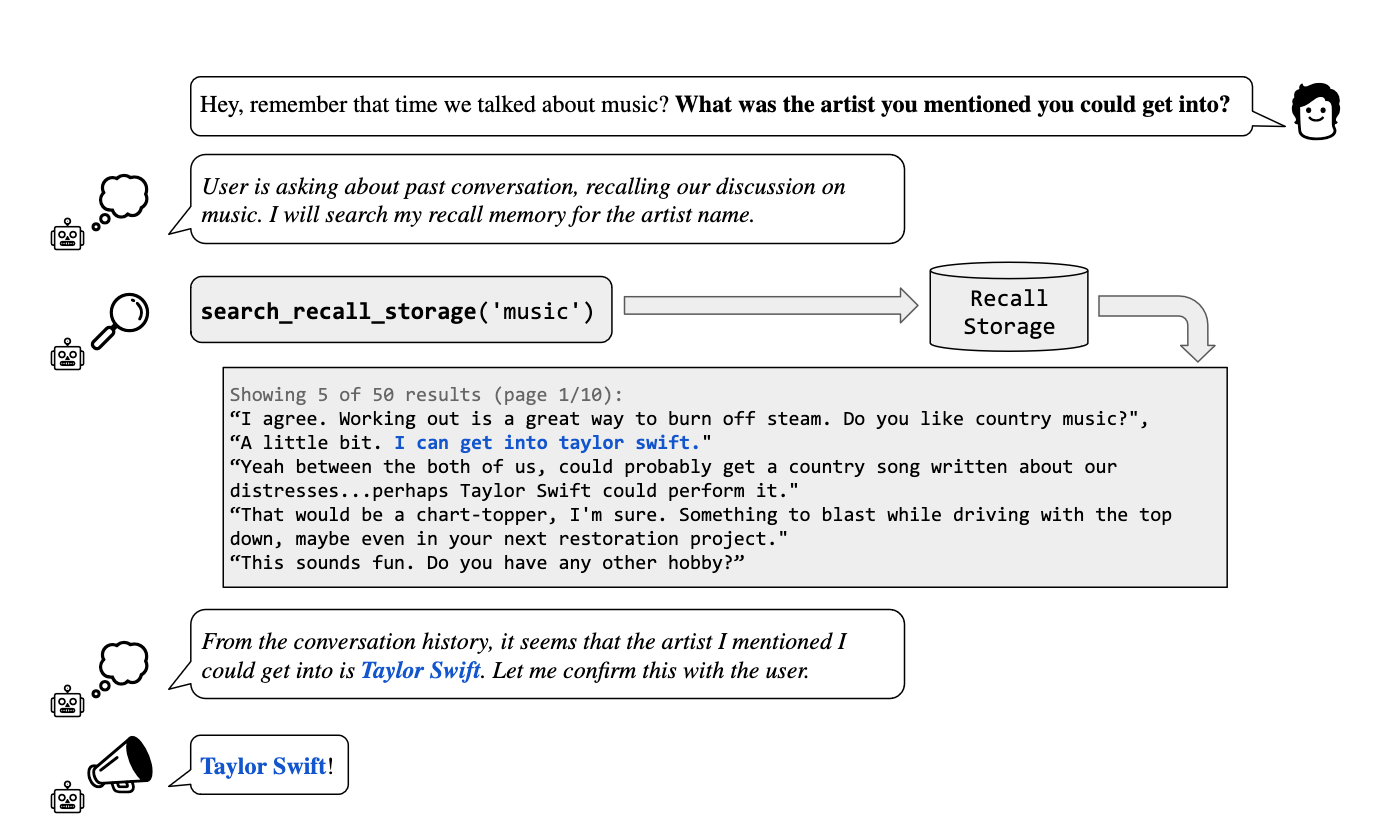
When the user asks the AI to recall a specific detail from a past conversation—in this case, an artist they mentioned they could get into—the AI doesn't have the answer immediately available in its current context window.
To find the answer, the AI performs a search in its "Recall Storage," which is a repository of information from prior conversations that are no longer in the immediate context window. The system searches this storage with the keyword 'music' to retrieve relevant past conversation snippets.
Upon searching, it finds several mentions of "Taylor Swift" in the conversation history, allowing the AI to infer that this was the artist the user was referring to. The AI then confirms this with the user, responding with the artist's name, "Taylor Swift!"
This demonstrates the AI's ability to remember and retrieve information from beyond its immediate context window, mimicking a more human-like ability to recall past interactions.
To assess the effectiveness of MemGPT and its counterparts, evaluation was conducted using the Multi-Session Chat (MSC) dataset featuring chat logs with consistent personas across sessions.
A new task, 'deep memory retrieval' (DMR), tests the consistency of conversational agents by asking them questions that refer back to previous sessions.
DMR questions require answers using knowledge from past sessions.
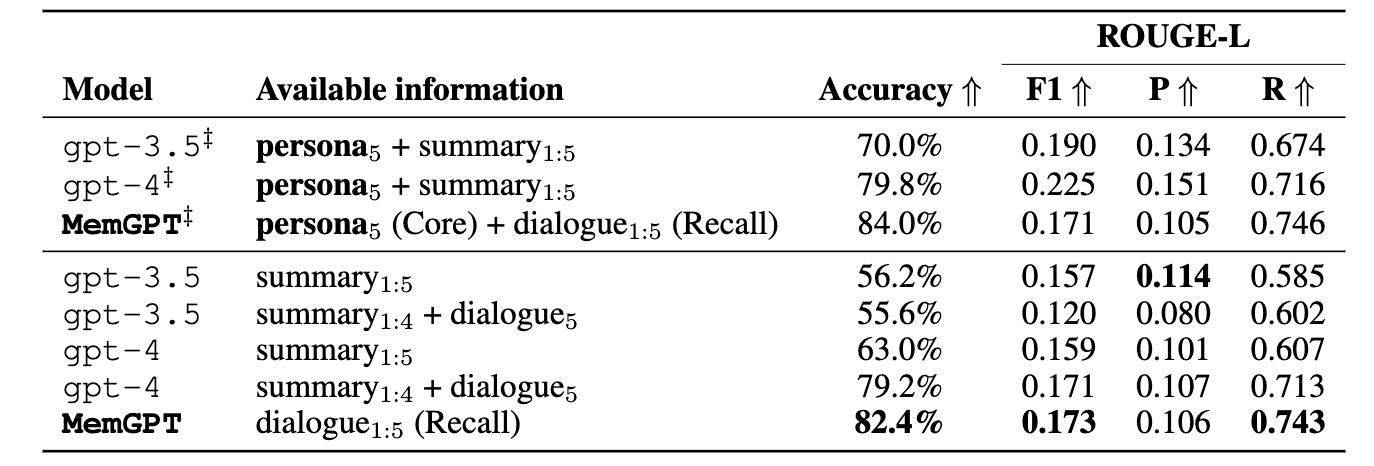
Accuracy: This measures the percentage of responses from the AI that were exactly correct compared to a "gold" standard answer.
F1 Score (F1): A harmonic mean of precision and recall, showing the balance between accurately retrieved information (precision) and the completeness of the retrieved information (recall).
Precision (P): Out of all the information retrieved by the AI, the proportion that was relevant or correct.
Recall (R): Out of all the relevant information available, the proportion that the AI successfully retrieved.
Summary:
MemGPT's approach to memory utilizes past conversation history for coherence, showing better performance than fixed-memory baselines in both LLM judge accuracy and ROUGE-L scores.
GPT-4 outperforms GPT-3.5 among the fixed-context models, especially when they have access to the full content of the most recent conversation.
Performance drops when a model relies only on a summary of past conversations rather than having access to full dialogues, as expected due to less information being available.
MemGPT's superior performance is attributed to its ability to recall past conversations from its memory, rather than relying solely on summaries.
Looking ahead, this methodology holds promise for further applications in various domains requiring expansive context management and could lead to the integration of diverse memory technologies.
Coming to some of the current limitations, proprietary models like OpenAI's GPT-4, which are finely tuned for function calling i.e the ability of the language model to interpret and execute specific commands or functions as part of its processing. Future improvements in open-source models and fine-tuning practices will get us closer to AI agents who remember what you said an year ago and refuse to answer your questions :’)
In the next part we will deep dive into the code and understand the nuts and bolts of this proposed architecture.
Until next time 👋
Further Reading:
For an in-depth look at tokenization, and to know more about BPE check out the Hugging Face Tokenization Course on Hugging Face.
To understand the innovative MemGPT model in detail, read the paper "MemGPT: Memory-augmented Pretrained Transformers" by Packer et al. (2023) on arXiv.
Visit the MemGPT Official Website for more information and updates on the project.
Dive into the code and contribute to the development on the MemGPT GitHub Repository.
